
The Compute-Optimal Approach to Training large language models (LLMs)
Google's research explores compute-optimal LLM training, comparing weak vs. strong models. Efficient techniques boost performance with limited resources. Study covers cost-effective methods, synthetic data use, and best practices. Learn how to optimize LLM training for better results.


Google recently made a bold claim. A claim that, in simple words, challenges the notion, “efficient LLMs need extensive resources to be created.” They have come to the conclusion that an LLM built on “Weaker and Cheaper” models offers more diverse results, with greater coverage and comparable false positives, when measured against a more LLMs built on Expensive, Stronger, and Complex models. Let me break that idea down before diving deeper.
Large Language Models (LLMs) are build, in most cases, using data available on the internet. These models are then refined, retrained and tested, before being offered as a viable product for its eventual mass market adoption. The levels of refinement an LLM goes through is subject to the amount of resources—monetary, manpower or otherwise—developers of that specific LLM are ready to spend. Therefore, common sense tell us that the more someone spends on an LLM, the better results they can expect as an outcome. But, Google says, this idea may not be true at all.
And, we sort of agree on this principle at Codemonk, verified through our internal findings across several enterprise use cases thus far. I will get to that part later, I promise. But lets first address Google’s claim and dissect it a little more.
The Claim:
In their research paper titled “Training LLM Reasoners Via Compute-Optimal Sampling,” Google explores the efficiency of training large language models (LLMs) using synthetic data generated by weaker but cheaper models (WC) compared with data generated by stronger but more expensive models (SE). It is important for any reader to contextualize this claim first, before proceeding ahead in the article.
When measuring the efficiency of any LLM, convention dictates that we consider synthetic data as input. What I mean by that is, synthetic data, or in technical terms, machine generated data is considered to be the best type of input when calculating the efficiency of any LLM, as opposed to the human data, which could include anomalies. As a result, Synthetic Data is better suited as a yardstick to measure the capabilities of an LLM. And with this valid assumption in place, as Google establishes, it is possible to define the refinement of the synthetic data that is fed in as an input.
For a broader understanding, lets consider that all existing LLMs to fall in two categories:
- Weaker but Cheaper LLMs (WC): Weaker but Cheaper (WC) LLMs are usually open source alternatives or free for use or come packed as a community edition, with a small price to pay for commercialization. For example, GPT-NeoX by EleutherAI or BLOOM are packaged in smaller buckets for specific use cases.
- Stronger but Expensive LLMs (SE): Typically industry leading LLMs known for their complex reasoning and problem-solving abilities, which also carry a hefty price tag with them when deployed for enterprise use cases.
Now, what Google tried to understand through this effort is “if training LLMs with data from weaker models is more compute-optimal than using stronger models under a fixed inference budget.” In simpler terms, for a fixed budget, what are the capabilities achievable using a WC model when compared with an SE model, and which of two carry greater viability as a enterprise solution?
To arrive at a conclusion, they looked at the coverage, diversity and false positive rate documented through both WC and SE models within the same budget.
Important to note:
Coverage, refers to the number of unique problems solved through either WC or SE
Diversity, refers to the number of unique solutions documented per problem
False Positive Rate, refers to the number of incorrect reasoning tasks carried out which lead to a correct answer.
The Test:
With these boundary conditions established, Google tried to understand if WCs outperformed SEs. And the team’s findings are surely noteworthy for an enterprise wishful of embarking on the AI/ML journey.
Google found that, WC models generated more samples within the same compute budget allocated, leading to higher coverage and diversity, but also recorded a higher false positive rate (FPR) for the same reason. SE models on the other hand prevailed shorthanded, mainly restricted by the budget allocation, thus leading to lesser samples, lower coverage and barely showcasing any diversity at all.
They inferred that models finetuned on WC-generated data consistently outperformed LLM models trained on SE-generated data across every benchmark established. Below is an excerpt from the research paper.
Given a fixed sampling budget, one can either generate fewer samples from a stronger but more expensive (SE) model or more samples from a weaker but cheaper (WC) model. The latter may lead to solving a wider range of problems and also more correct solutions per question. We compare the utility of these two synthetically generated datasets for training LM reasoners in various supervised finetuning setups and show that training with the data from WC consistently outperforms training on data from SE.
Google then finetuned the two LLM models for three specific capabilities (Knowledge Distillation, Self Improvement & Weak-to-Strong Improvement)to measure Pass@1 accuracy. Let me explain:
- Knowledge Distillation happens when one LLM learns from another LLM, with a master and apprentice like relationship, one following the other
- Self Improvement happens where an LLM—through multiple refinements—learns to Self-Generate Data
- Weak-to-Strong Improvement is when A stronger LLM improves data from a weaker LLM
Here Pass@1 accuracy measures the percentage of problems for which the model’s first generated output is considered correct. For a better understanding, we can come to the assumption that Pass@1 accuracy is calculated by taking the number of problems where the first solution provided by an LLM is correct, and dividing this result by the total number of problems solved by the same LLM.
These capabilities allow Google to evaluate the performance of language models for tasks involving the generation of new artefacts, with mathematical reasoning, code generation and more.
Lets simplify this with an analogy: Lets assume you have 100 problems, and you use an LLM to generate solutions for each problem. If the LLM’s first answer is correct for 80 of those 100 problems, then the Pass@1 accuracy for this LLM is 80 percent. Now lets apply this principle to two known LLMs.
The Result:
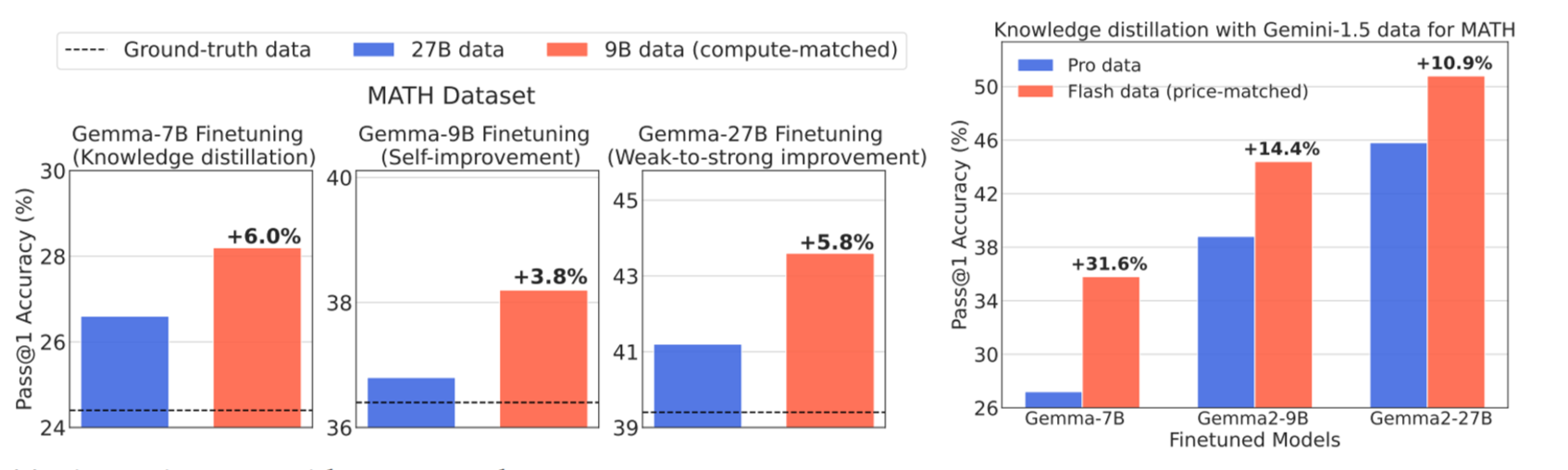
In the above graph, Gemma2-9B (Orange bar) is considered as the Weaker but Cheaper (WC) model, while Gemma2-27B (Blue bar) is the Stronger but Expensive (SE) model.
As noticed through the Pass@1 accuracy results, 27B (SE model) achieves a lower percentile when compared with 9B (WC model) for a fixed compute budget allocated. This means 9B (an LLM trained on WC model) produces more correct results in the first run, with greater coverage, diversity and lesser FPR (corrected through refinement), proving that money spent on developing a complex, highly specific LLM may not translate to resource efficiency.
Now that brings us to the enterprise wide applicability of LLMs in general when specific use cases are considered. The study, similar to our internal findings across enterprise use cases such as document intelligence, clearly proves that a compute-optimal approach is better suited to training LLMs, which among other things, can include looking at weaker but cheaper LLMs as a training data set when refining parent LLMs for discrete business use cases. Business leaders and enterprises alike can rest easy, as long as problems are correctly addressed by the LLM tasked for the job in fewer attempts. This is where problem solvers such as Codemonk come in, proving how their refinement strategies can solve the problem thrown to them in not just fewer attempt but rather in the very first attempt.
And we have done that through Document Intelligence as a Solution, which not only offers traditional OCR, NLP and NLU as capabilities but also provide business the much needed contextual intelligence within AI/ML products and services. Codemonk has validated that the performance gap between small and large LLMs can be narrowed down through intelligent and efficient engineering, using models that are not just resourceful, but also tailored to specific business areas.