
Unleashing Scalability with AWS Batch
AWS Batch is a fully managed batch computing service that plans, schedules, and runs your containerised batch or ML workloads across the full range of AWS compute offerings, such as Amazon ECS, Amazon EKS, AWS Fargate, and Spot or On-Demand Instances.


Introduction
Batch computing is the execution of a series of jobs or tasks without manual intervention, typically in a sequence or batches. It involves the automatic processing of data or computational tasks in large quantities. Batch computing simplifies complex tasks by allowing you to organise and process information in manageable chunks.
AWS Batch is a game changer service within the AWS ecosystem, which provides a fully managed platform for orchestrating and executing batch workloads. If infrastructure management is the Achilles heel, then AWS Batch is the answer to your problems.
In my past, I have used AWS Batch to run data pipelines that requires good amount of GPU. With AWS Batch, I have been effortlessly scaling the number of servers and changing the EC2 instance type based on workload. The various choices of GPU instances allowed me to dynamically change the type of GPU instance based on the size of the workload.
AWS Batch is very advantageous, especially for flexible scaling and cost optimisation. Without this service, I would have faced tons of hassle related to provisioning and maintenance of server infrastructure. Read on further to find on how you can run large scale, compute intensive batch jobs while simplifying the process of scaling the infrastructure.
What is AWS Batch?
An excerpt from AWS Batch Docs:
AWS Batch is a fully managed batch computing service that plans, schedules, and runs your containerised batch or ML workloads across the full range of AWS compute offerings, such as Amazon ECS, Amazon EKS, AWS Fargate, and Spot or On-Demand Instances.
It dynamically provisions the optimal quantity and type of compute resources based on the volume and specific requirements of your batch jobs, while removing the hassle of configuring and managing independent infrastructure.
Again from AWS Docs:
With AWS Batch, there's no need to install or manage batch computing software, so you can focus your time on analysing results and solving problems.
Key Highlights:
1. Dynamic Resource Provisioning:
- AWS Batch removes the undifferentiated heavy lifting of configuring and independent infrastructure services, similar to traditional batch computing software.
- It provisions compute resources and optimises the workload distribution based on the quantity and scale of the workloads.
2. Integration with Other AWS Services:
- AWS Batch seamlessly integrates with other AWS services, such as Amazon S3 for object storage, AWS Identity and Access Management (IAM) for access control, and Amazon Cloud-watch for monitoring and logging.
3. High Performance:
- By harnessing the power of EC2 instances, AWS Batch can handle thousands of batch computing tasks. This provides a strong solution for high-performance computing needs in various areas like finance, visual effects, and machine learning.
4. Cost Optimisation:
- Users can create custom compute environments consisting of either Fargate or EC2 instances, specifying the type and quantity of EC2 instances to be used.
- AWS Batch gives the flexibility to choose between On-Demand, Spot, and Reserved Instances for the compute resources. Leveraging Spot Instances can significantly reduce costs, making AWS Batch a cost-effective solution for batch processing.
Usage Scenarios:
AWS Batch’s ability to dynamically scale compute resources, makes it a valuable solution for organisations looking to optimise and streamline their batch computing workflows in the cloud.
Here are some common usage scenarios for AWS Batch:
- Data Processing and ETL: It is well suited for cleansing, normalisation, processing, enriching and transforming large volumes of data.
- High Performance Computing & Simulations: Researchers and scientists can use AWS Batch for running complex simulations, scientific computations, and numerical modelling.
- Media Processing & Rendering: Video encoding, format conversion, and rendering of computer-generated imagery (CGI) can be distributed across multiple EC2 instances to accelerate processing.
- Machine Learning Model Training: Training large models or running hyper-parameter tuning jobs can benefit from the parallel processing capabilities of AWS Batch.
- Batch Analytics: Batch analytics jobs can be scheduled to process data at regular intervals, ensuring up-to-date insights for decision-making.
Notably, AWS Batch excels in handling long-running and resource-intensive batch operations, overcoming limitations in time, memory, or computing resources that other AWS services may encounter.
Terminologies:
Let’s understand some common terminologies associated with AWS Batch.

1. Job Definition:
- In AWS Batch, a job definition serves as a blueprint for running a batch job. Think of it like a set of instructions that tell AWS Batch how to execute a particular task.
- These job definitions are handy because they package up all the important details of a job, including things like what container image to use, how much CPU and memory it needs, where to find input data, and where to put the output.
- The beauty of job definitions is that once you've created one, you can use it over and over again to run multiple instances of the same job, ensuring consistency in every run.
2. Job Queue:
- Job queues hold your jobs until they're ready to run on a compute environment.
- They help organise and group your jobs logically.
- Each job queue has a priority, which tells the system which jobs to run first.
- A job queue can be linked to one or up to three compute environments, but you can't mix EC2 and Fargate in the same queue.
3. Compute Environment:
- Compute environments are where your batch jobs run.
- Each compute environment can be linked to one or more job queues.
- They handle the infrastructure needed to run your batch tasks, and AWS Batch takes care of managing resources like CPU and memory automatically.
4. Job:
- A Job is the unit of work that's started by AWS Batch.
- It can be a script, an application, or any executable code that is encapsulated within a Docker container.
- To run a batch job using AWS Batch, you submit a job to a specific job queue, referencing a particular job definition. AWS Batch then uses the job definition to create and launch the necessary compute resources and execute the job according to the specified parameters.
Choosing the Right Compute: Fargate vs. EC2
Fargate and EC2 are two services used by AWS Batch for running batch workloads. Fargate is like a "server-less" option for running containers, meaning you don't have to worry about managing servers. On the other hand, EC2 provides resizable computing power in the cloud.
For most cases, AWS suggests using Fargate. It automatically adjusts the computing resources based on what your containers need, saving you from the hassle of managing servers. With Fargate, you only pay for the resources you use and don't have to worry about over-provisioning or paying for extra servers. It's a simpler and more cost-effective way.
However Fargate has limitations, AWS recommends that EC2 should be used if the jobs require any of the following:
- More than 16 vCPUs.
- More than 120 gibibytes (GiB) of memory.
- A GPU: Since Fargate does not support GPU.
- A custom Amazon Machine Image (AMI)
- Or any of the linuxParameters.
Running an AWS Batch Example on Fargate

Let's kick things off by running a simple 'hello world' application using AWS Batch on Fargate.
Keep in mind that in real-world scenarios, this sample application can be swapped out for any other application, service, or script.
1. Create docker file.
Create a file hello.py with the following line in it.
print("Hello From AWS Batch")
Create a Docker file which executes the above script.
# Use an official Python runtime as a parent image
FROM python:3.12.1-alpine
# Set the working directory to /app
WORKDIR /app
# Copy the current directory contents into the container at /app
COPY . /app
# Run hello.py when the container launches
CMD ["python", "./hello.py"]
2. Push Docker Image to ECR Repository.
Create an ECR repository. Build the above Docker file and push it to the newly created ECR repository.
3. Create Compute Environment.
Go to the AWS Batch service from the AWS Console. You will land on the AWS Batch dashboard. Navigate to the Compute Environment section from the side bar. Click on the Create button on the top left hand side of the page to create your first compute environment.
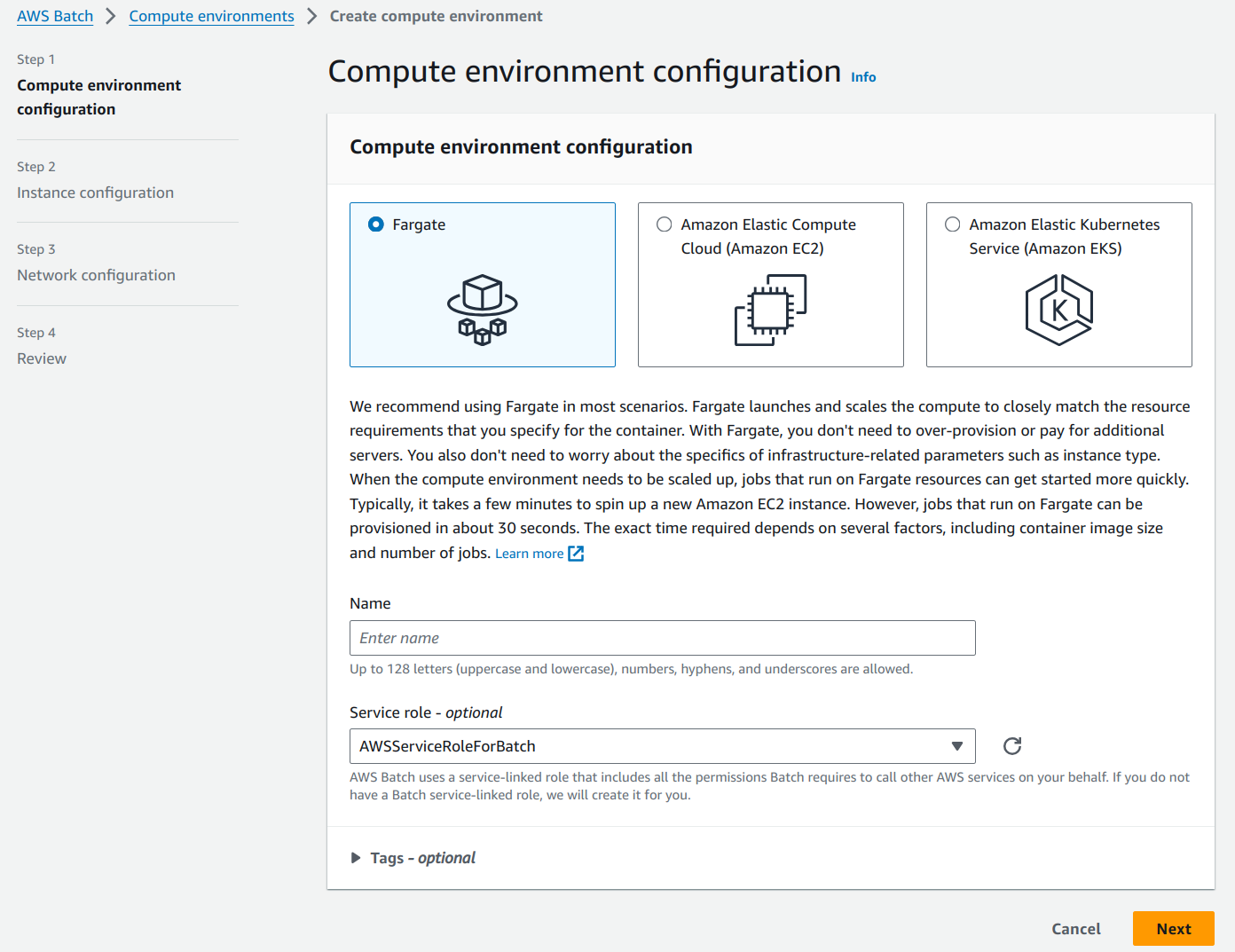
Fargate is selected as the default option for the type of Compute Environment. Give an appropriate name for the environment. I am giving the name Fargate CE and moving ahead with the default options as shown below.
Clicking on the Next button takes you to the “Instance configuration” page.
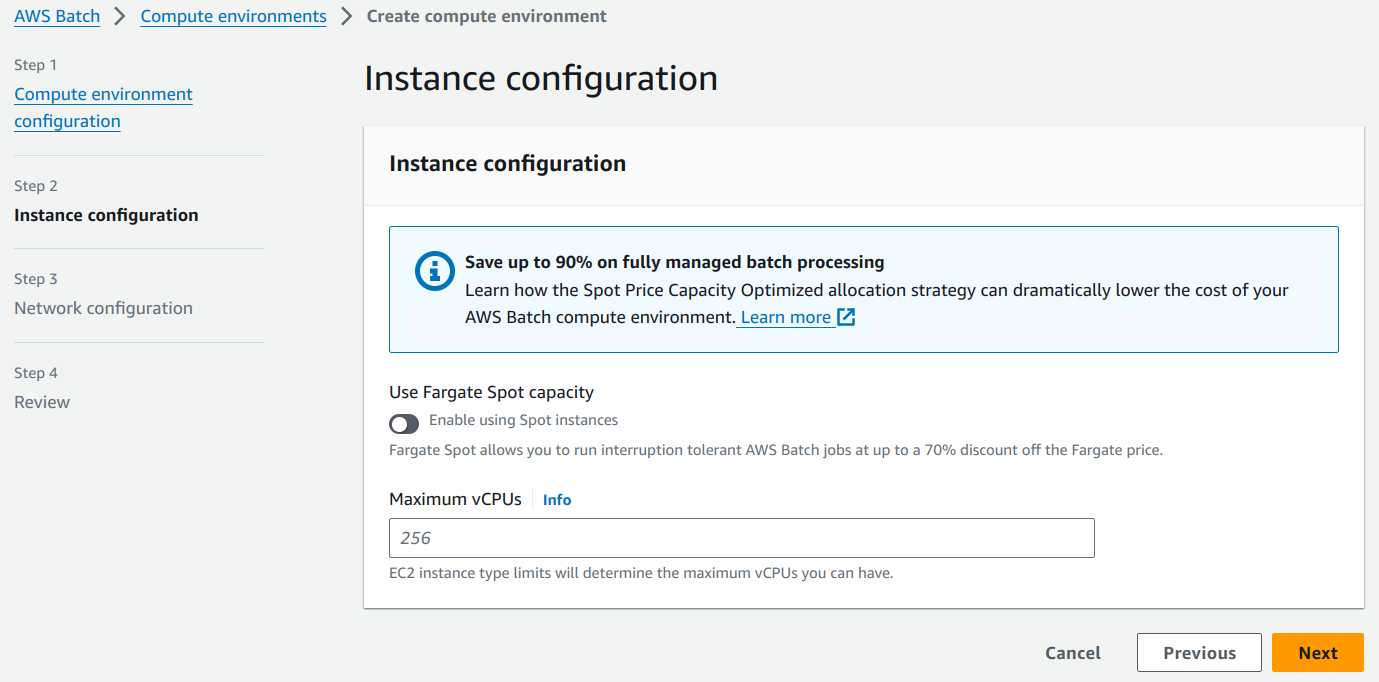
Maximum vCPUs represents the number of vCPUs that your compute environment can scale out to, regardless of job queue demand. Let’s put 4 vCPUs as shown below.
Clicking on the Next button, takes you to the “Network configuration” page.
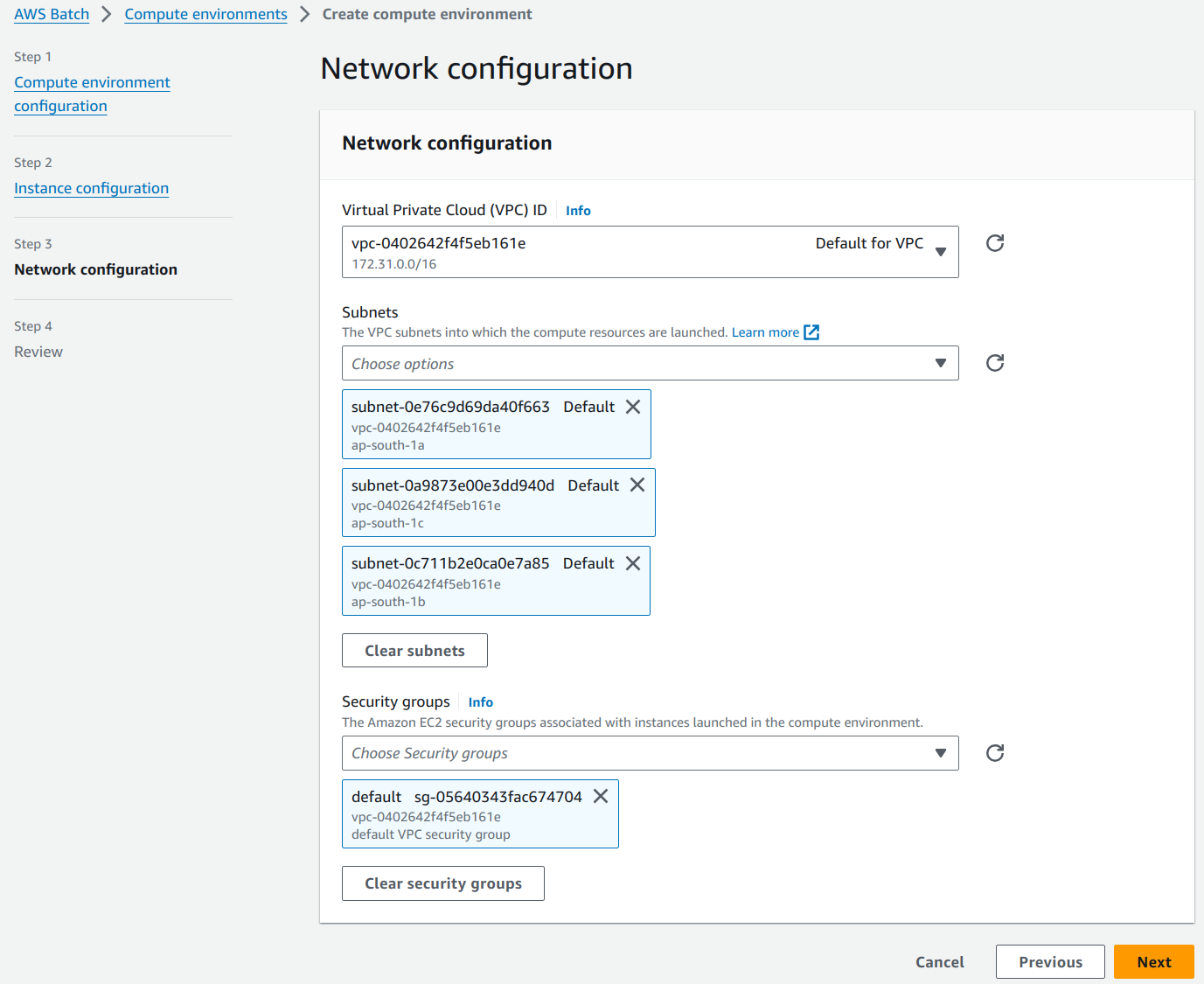
Create VPC, Subnets and Security Groups from the VPC Dashboard and select them over here.
The next page is the “Review” page. Review the entire compute environment configuration and click on the “Create compute environment” page to create your first compute environment.
4. Create Job Queue.
Navigate to the “Job queues” section from the side bar. Click on the “Create” button on the top left corner of the “Job queues” page.
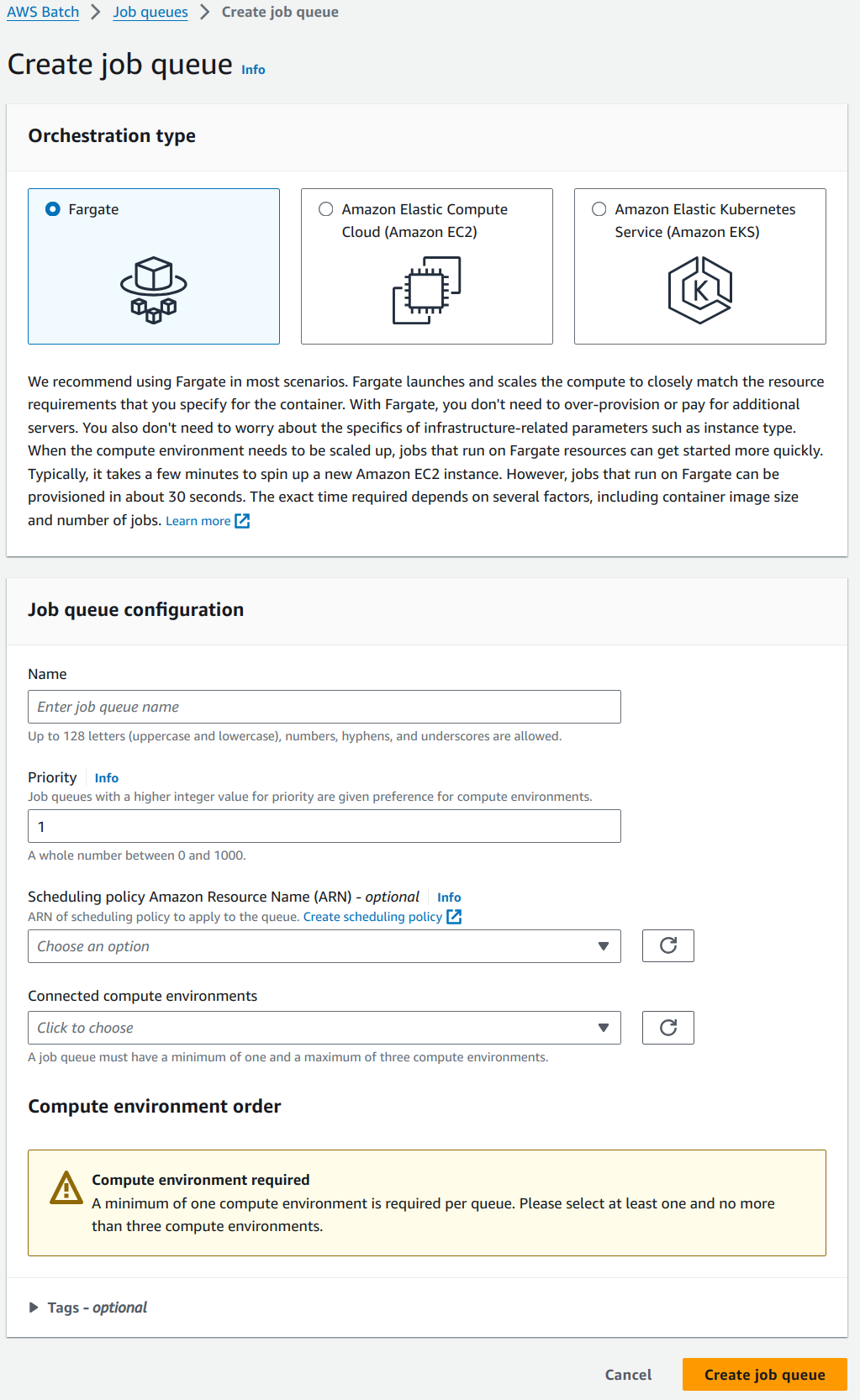
Select the newly created “FargateCE” environment in the “Connected compute environments” drop down. Priority represents the order in which the job queues are given preference in a compute environment. We will be using the default value as there is only one job queue in the compute environment. Create a job queue with name “FargateJQ”.
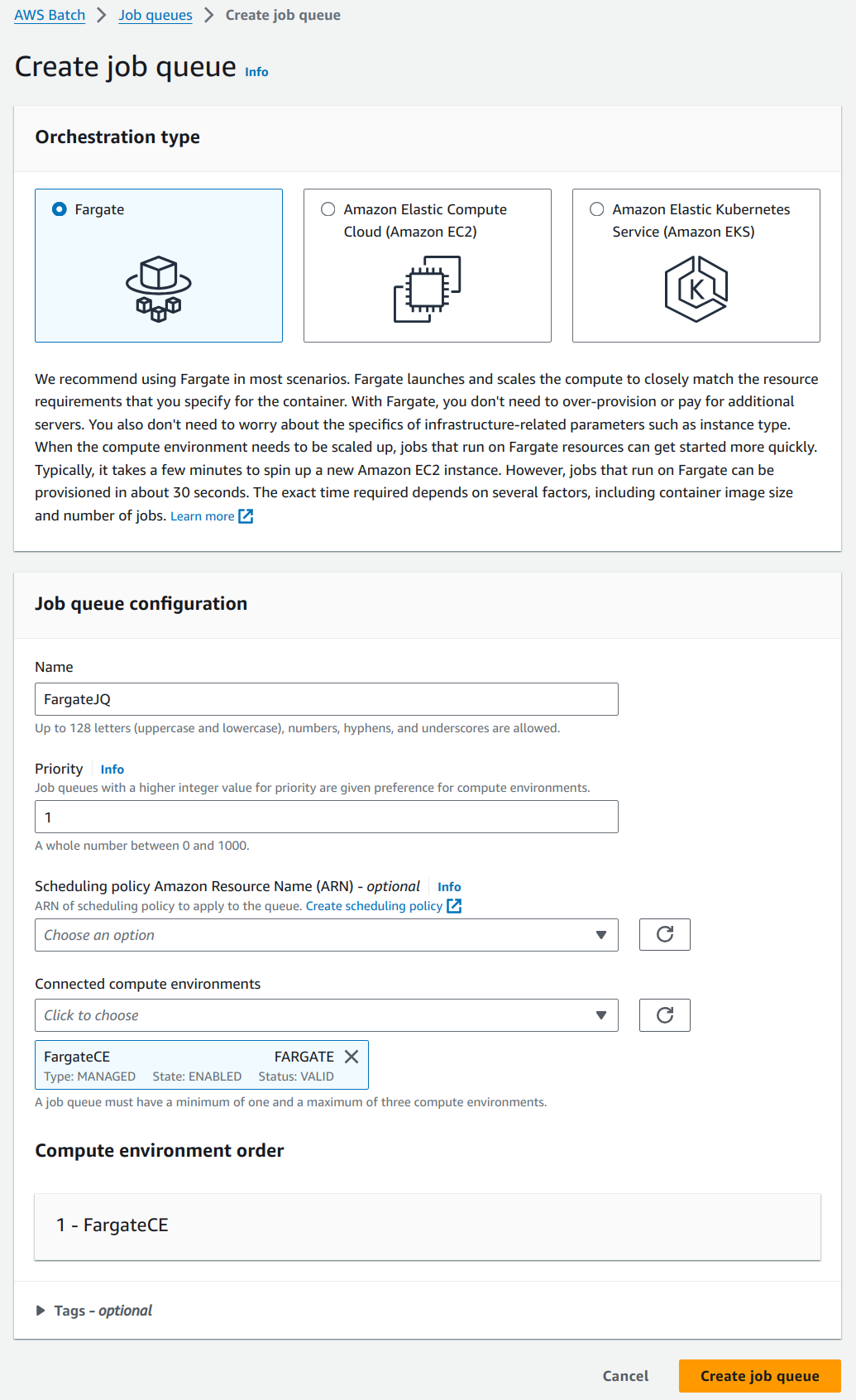
5. Create Job Definition.
Navigate to the “Job definitions” section from the side bar. Click on the “Create” button on the top left corner of the page.
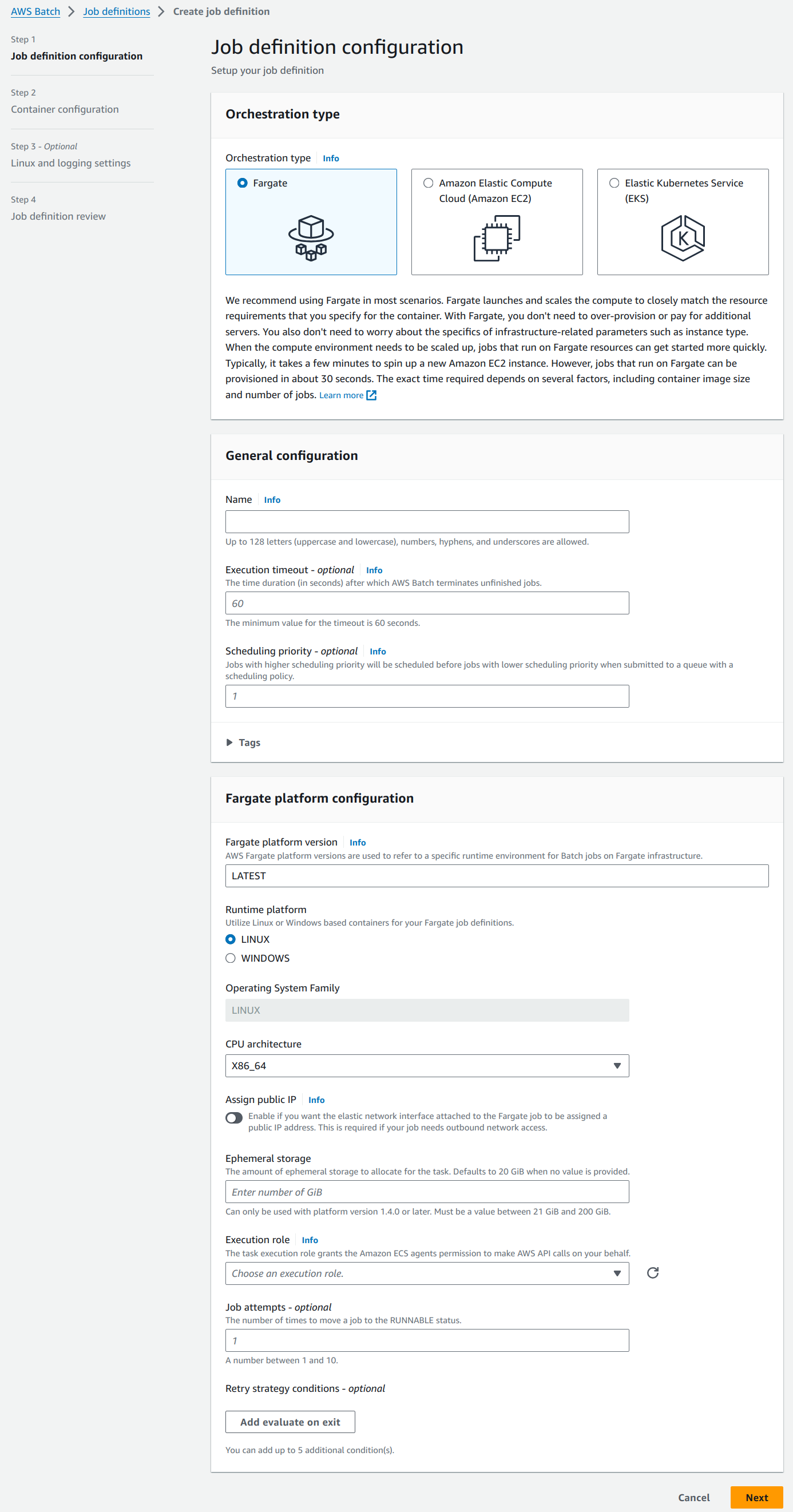
Our job definition will be named “HelloWorldJobDefinition”. Create an IAM role with ECS permissions and use it in the execution role as shown below. Toggle “Assign Public IP” to enable outbound network access to pull the ECR image. For the rest of the values, we will go with the default options.
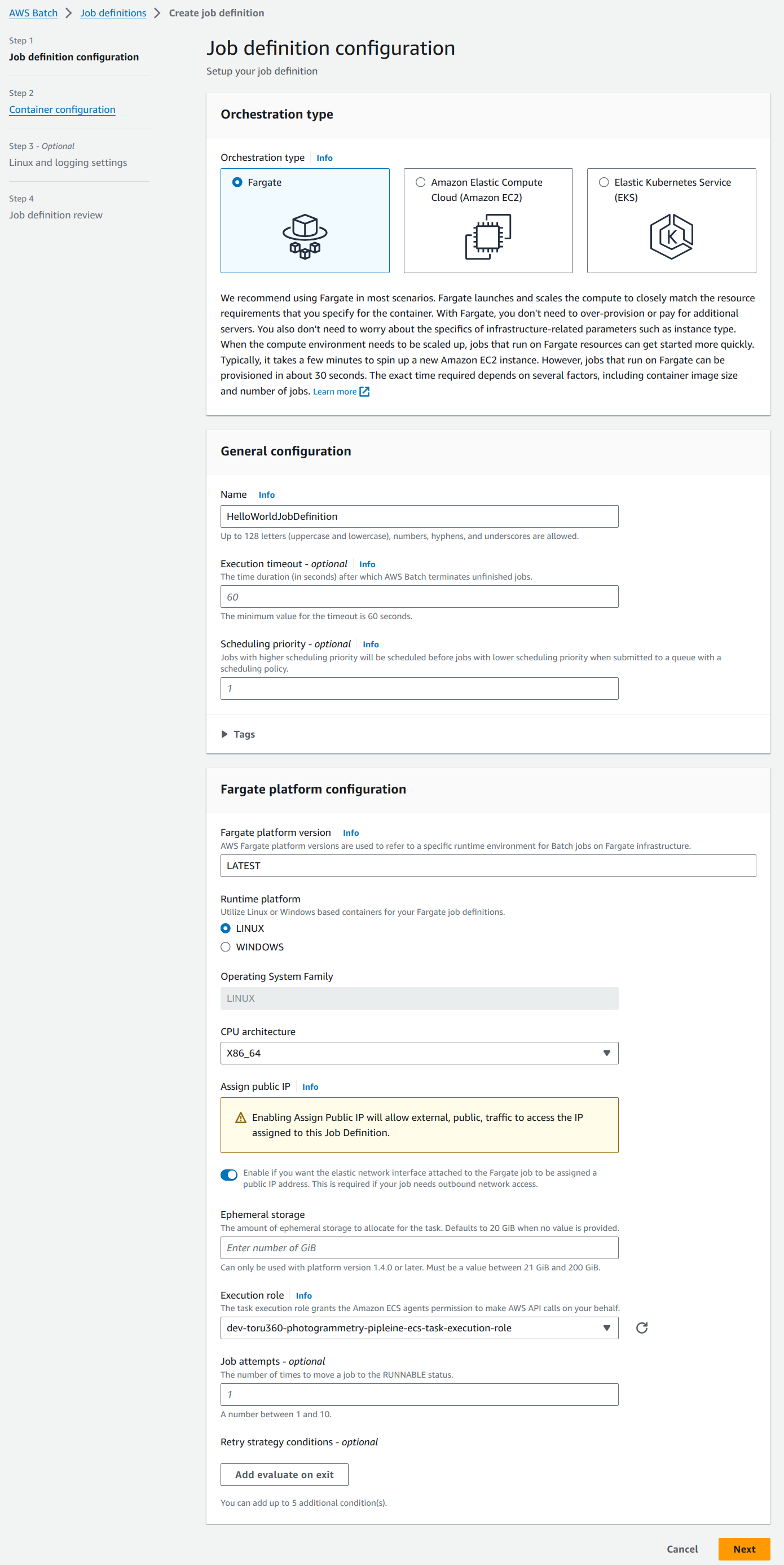
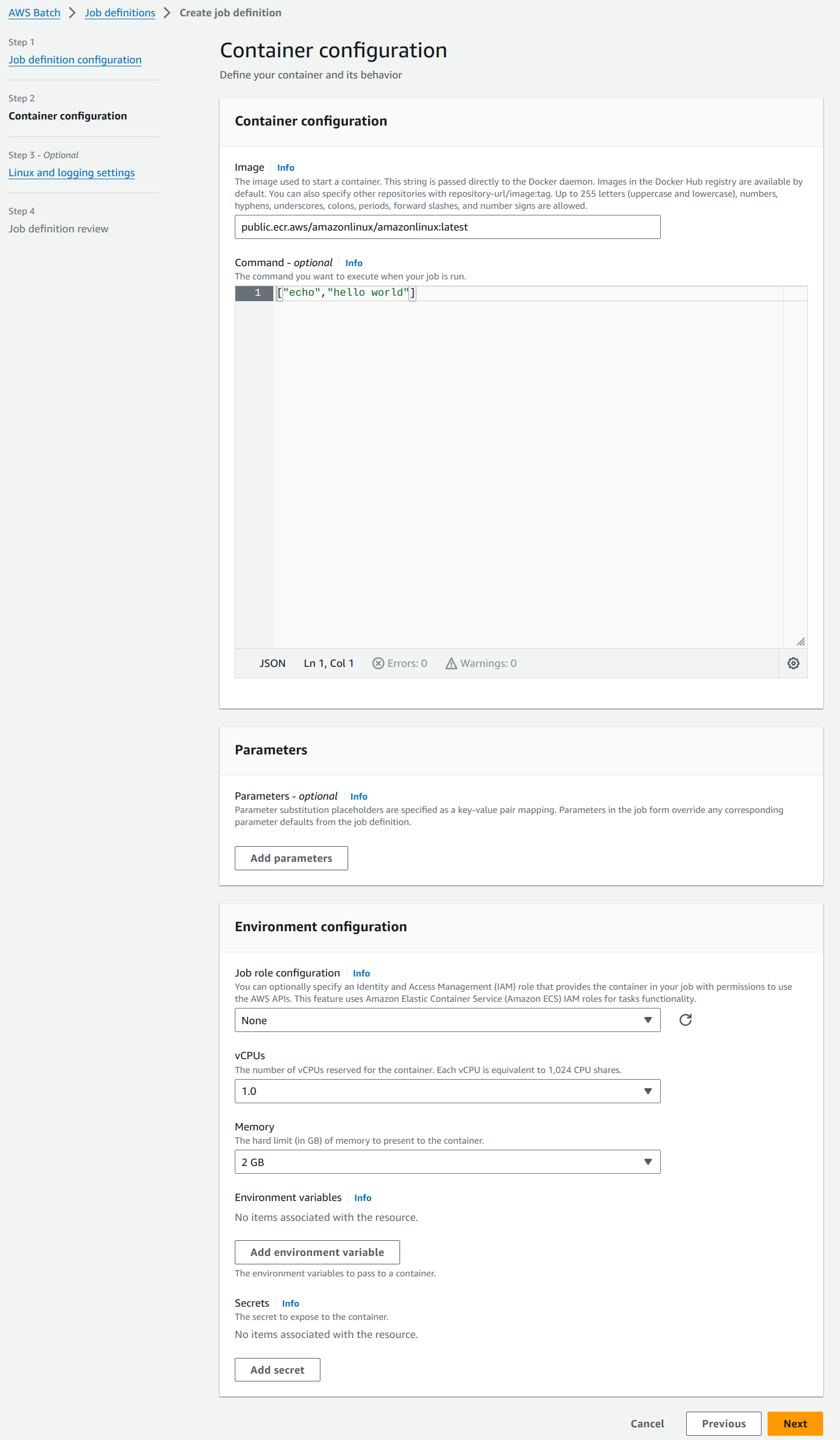
On the next page, use the docker image pushed to the ECR in the Image field. “Command” is an optional field which can be used to fire a script, app, command, etc. In our case, the Docker file executes the python script and hence the field can be kept empty. Proceed with default options for the rest.
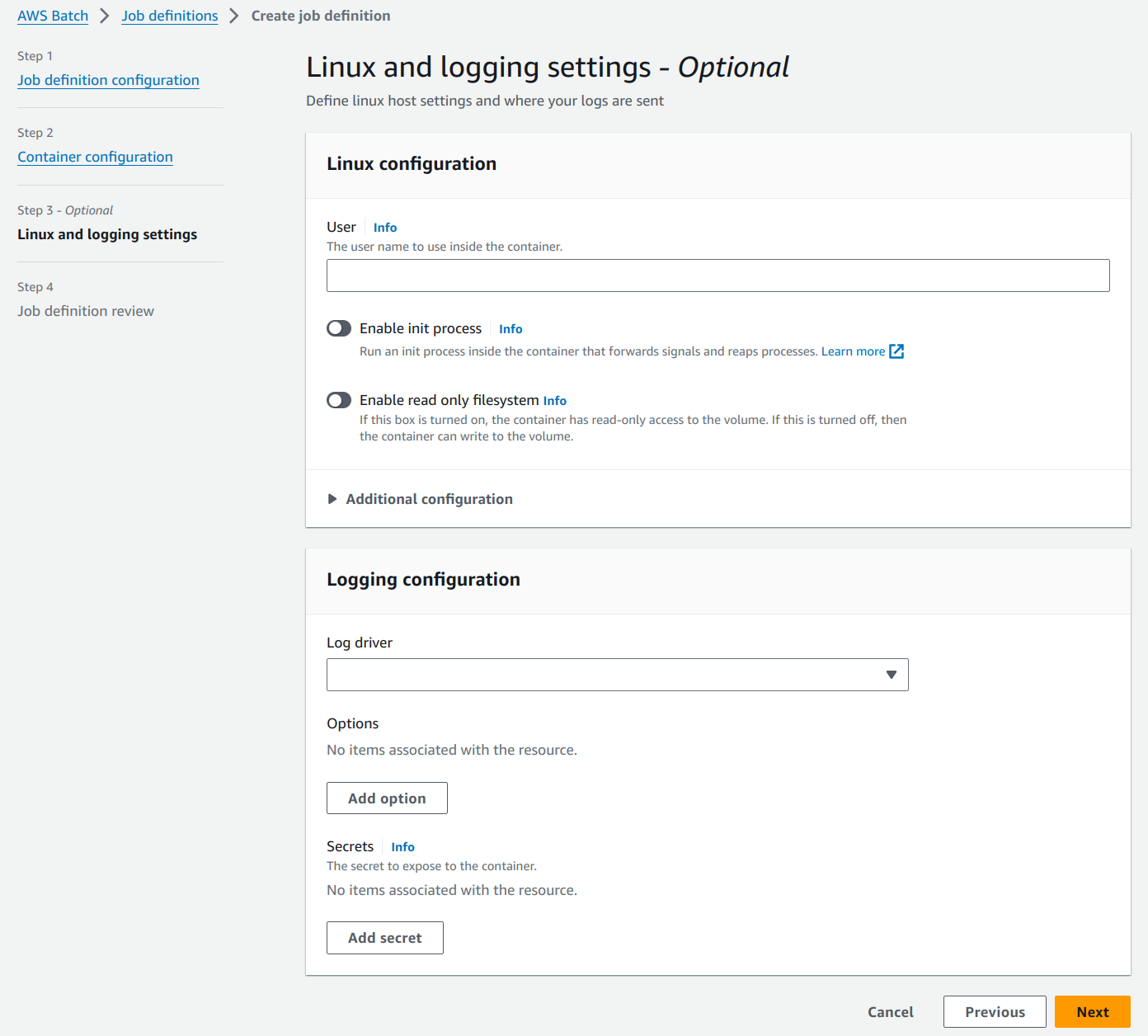
The next “Linux and logging settings” is a page with all optional settings and we will proceed with the default options.
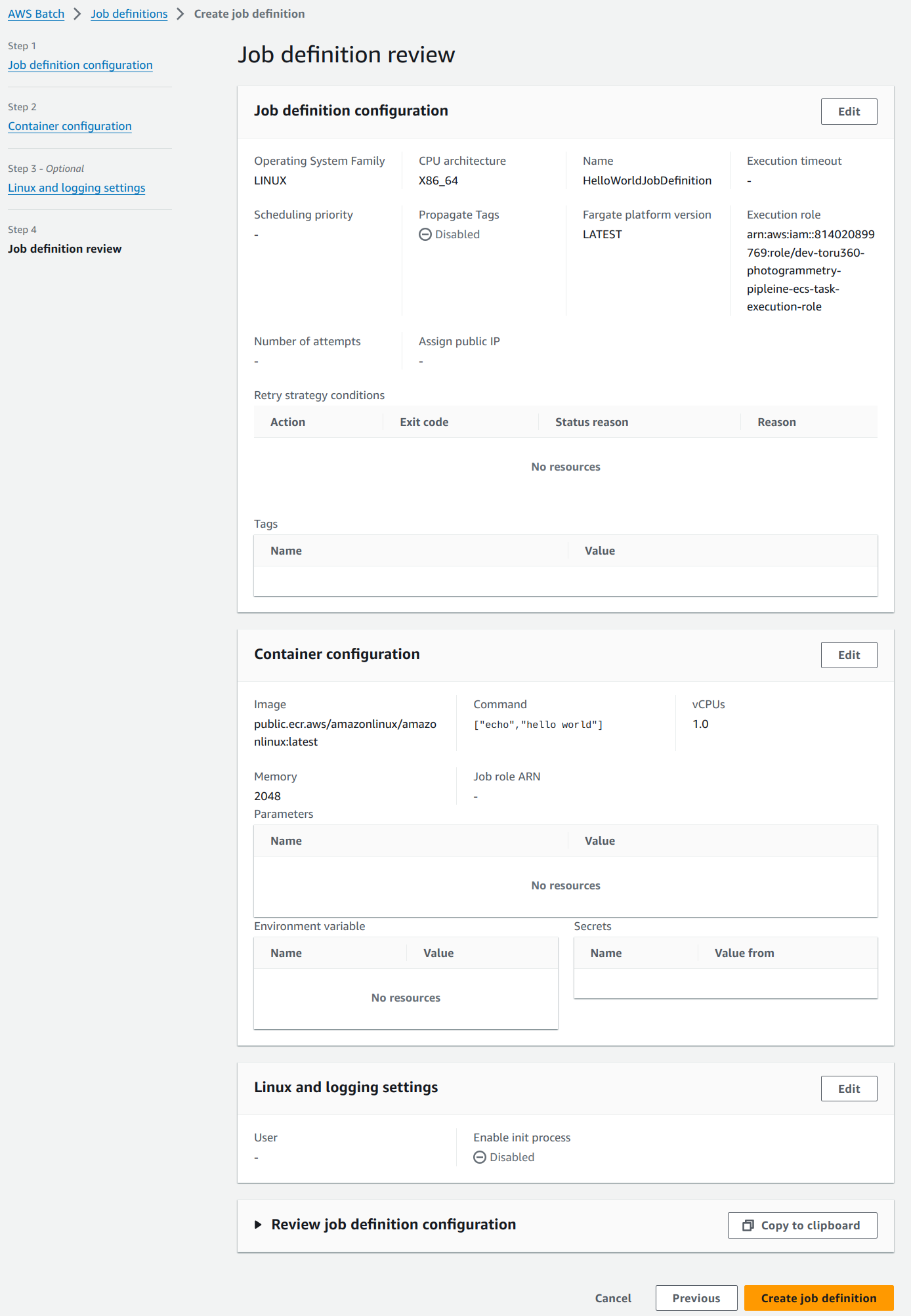
Review the settings in the last page and create the job definition.
6. Submit a job.
Navigate to the “Jobs” section in the side bar. Click on the “Submit new job” button on the top left corner of the page.
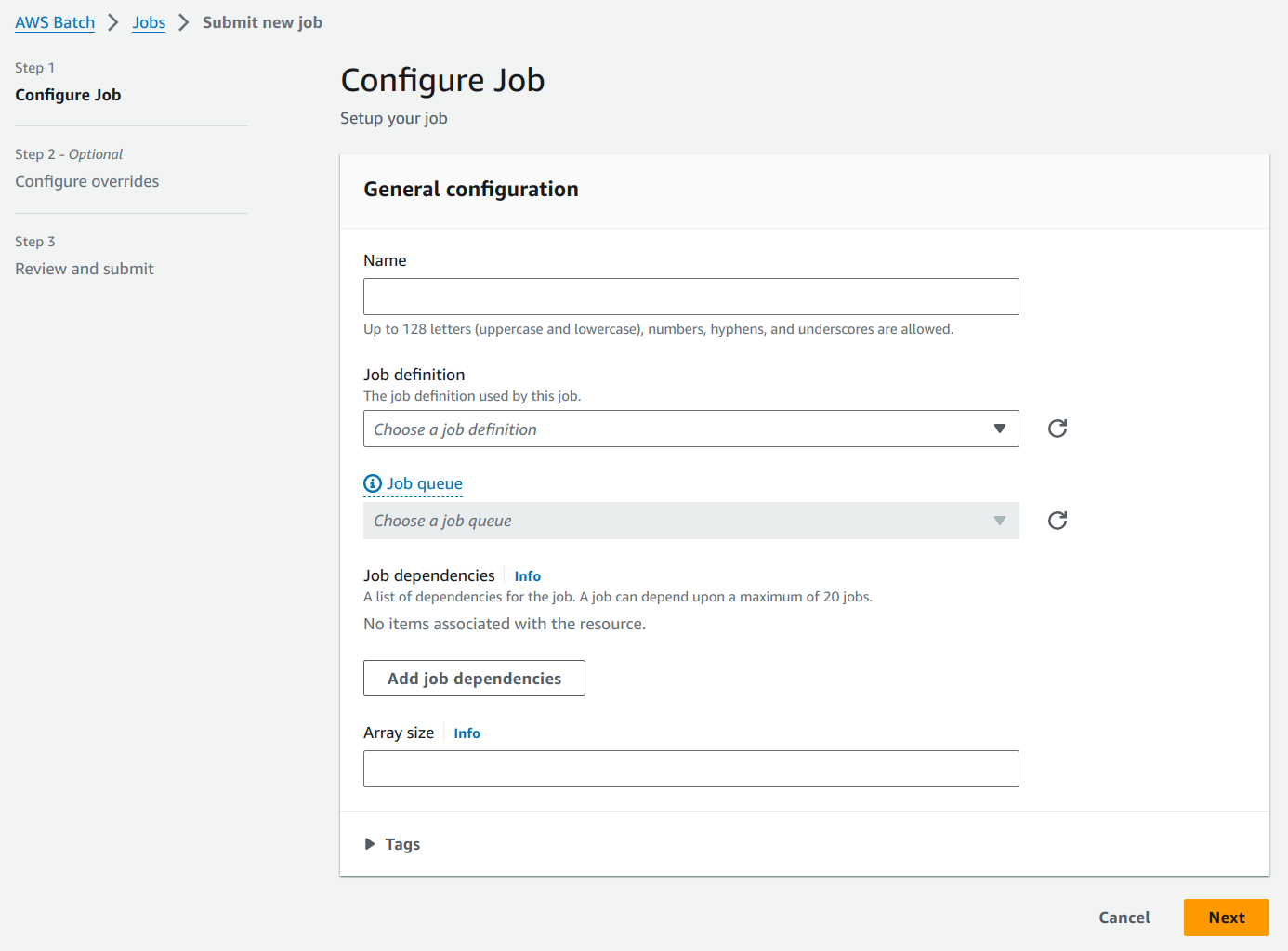
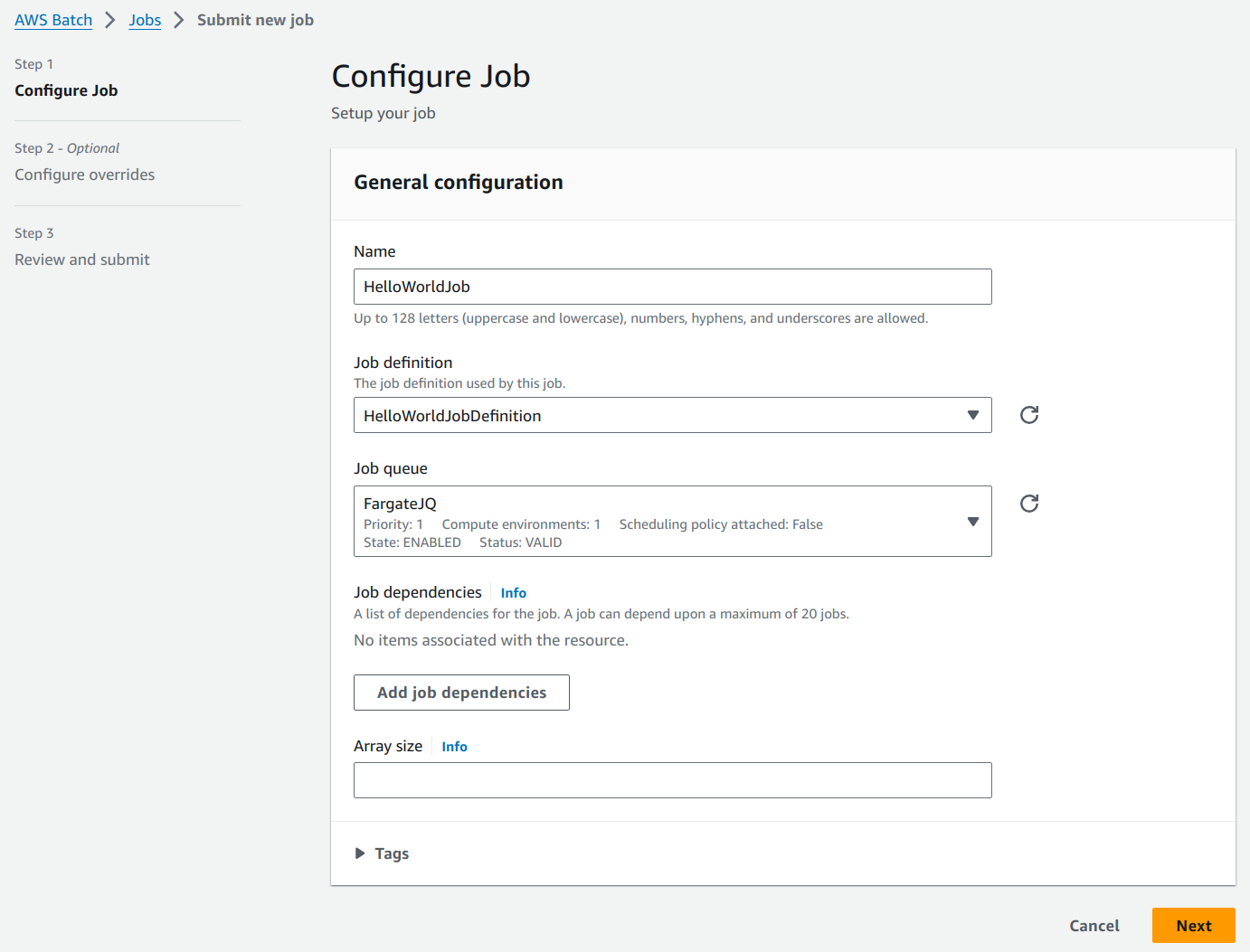
We will name our job as HelloWorldJob. Select the above created job definition and job queue from the respective fields.
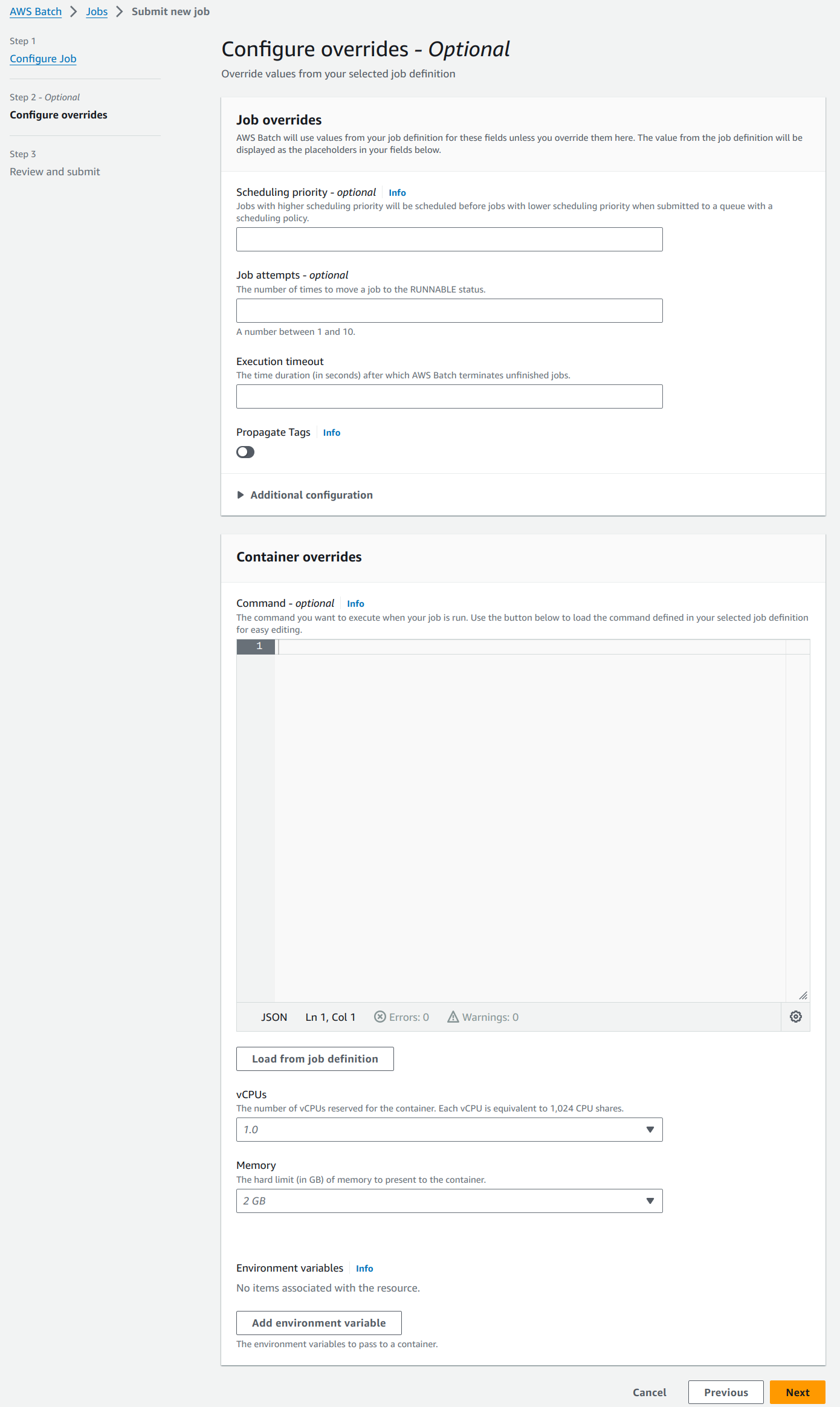
“Configure overrides” page has default optional fields. It can be used to override job definition properties while submitting the job. We will proceed with the default values.
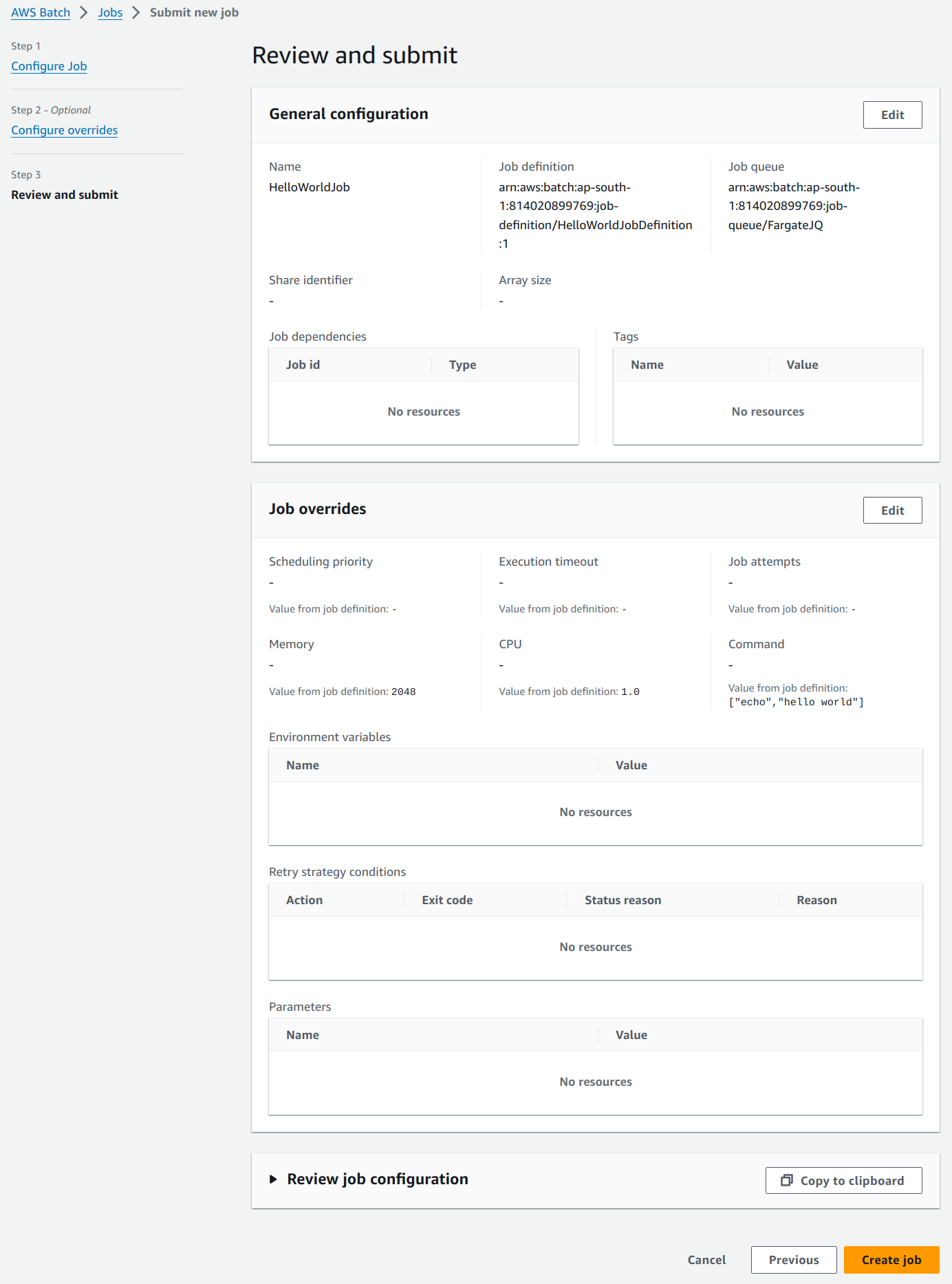
Review and submit the job in the next page.
The submitted job’s status will change in the below given order.
- Submitted
- Pending
- Runnable
- Starting
- Running
- Succeeded
From the AWS docs:
SUBMITTEDA job that's submitted to the queue, and has not yet been evaluated by the scheduler.
RUNNABLEA job that resides in the queue, has no outstanding dependencies, and is therefore ready to be scheduled to a host. Jobs in this state are started as soon as sufficient resources are available in one of the compute environments that are mapped to the job's queue.
STARTINGThese jobs have been scheduled to a host and the relevant container initiation operations are underway.
RUNNINGThe job is running as a container job on an Amazon ECS container instance within a compute environment.
SUCCEEDEDThe job has successfully completed with an exit code of 0.Every job has log stream attached to it which can be used to check the logs of our docker container.
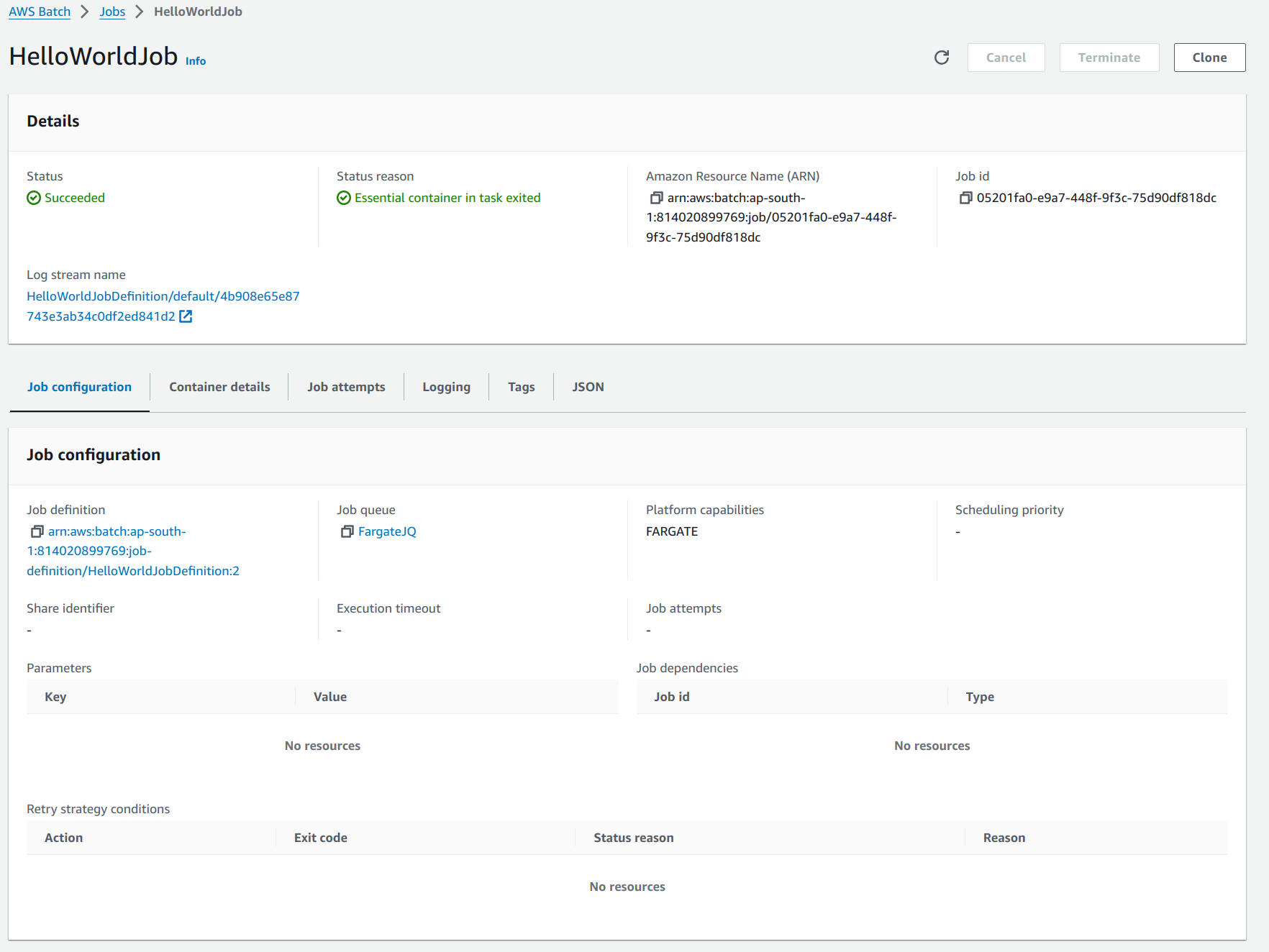
The Docker file and the command used in the above job can be replaced by any other Docker file, script, app, command, etc to take advantage of the Batch’s scalability and computing power on the fly. The AWS Batch service can also be started through client SDKs provided by the AWS.
Troubleshooting AWS Batch Jobs:

AWS Batch uses EC2, ECS, Fargate and few other services. There are a quite a few things that could go wrong while using Batch. AWS documentation provides comprehensive troubleshooting steps for all the underlying services to make our lives easier. You can read them over here:

Conclusion:
AWS Batch emerges as a robust solution for organisations aiming to effectively manage and scale their batch computing tasks. With its automated resource provisioning, seamless integration with other AWS services, and flexible job definition and scheduling capabilities, AWS Batch enables businesses to prioritise their core applications while ensuring optimal performance and cost-effectiveness.
As the demand for scalable and cost-efficient computing solutions continues to grow, AWS Batch maintains its position as a key player in meeting these evolving needs.
Want more insights and expert tips? Don't just read about AWS Batch! Work with brilliant engineers at Codemonk and experience it's effective use case firsthand!