
How to Guide an LLM - Flux Guidance Explained
This article explores Flux Guidance for LLM-based image processing, explaining diffusion models and how to control image generation using ComfyUI. Readers will learn step-by-step techniques to guide AI for creating and modifying high-quality images, perfect for professional and creative use cases.


As keen as anybody is to reap the rewards of generative AI tools, understanding the inner workings of LLM-based content creation methodologies gives creators an edge over those that simply use these tools to generate assets for enterprise distribution. Why have we felt the need to dissect image processing in this article, specifically one that is open-source, easily accessible, and reproducible for non-profit use cases to show you:
Why should anyone using GenAI pay attention to what happens on the inside?
For today’s explanation of image processing, generation, and modification using GenAI, let us consider the operating principles of a diffusion model. Now, before we explain what a diffusion model is, it is important to note that any user can essentially provide two types of image prompts: one that involves generating an image, an image, and one that involves modifying and understanding how an image is perceived by a machine. When an image is fed into a large language model (LLM) as input for image processing, the LLM perceives this input as canvas filled with noise. 90s kids can think of the grayish pixel-filled screen displayed by CRT television sets when the receiver lost transmission signals or failed to detect it for some reason. For a simpler example, let's assume that this CRT noise is what an image looks like to a computer running an LLM. When the computer is then asked to produce an output, particularly with tasks involving image processing, the LLM rearranges this pixel-filled (noise-filled) canvas in a specific order to produce a definite output. Meaning, pixels from the random noise are rearranged as per the instructions given in a specific sequence, guiding the LLM to bring a certain order to the randomness.
Broadly speaking, below are the two convention query types given to an image processing LLM.
Image generation queries (requests): the LLM can consider any random image as a reference on a noise-filled image considered as null input, which is then rearranged as per specific instructions in a particular order to match the image prompt fed in as text to generate the output.
Image modification queries (requests): An initial image is fed as a reference, within which specific portions or the image in its entirety is modified to obtain the final output using guidance protocols.
Let us consider the latter of the above cases (which includes key takeaways from the former) with an example to explain how guidance works for an LLM.
Task at hand: Edit an existing portrait of a man dressed in a beige suit with a dull background, making the photo more appealing. Brighten the image, make the suit pop out (by changing the color maybe), and improve the background and lighting conditions to obtain an output that closely resembles the output delivered by a professional photographer after post-processing.
Input:
- Image input: The raw image captured on a smart phone camera can become the input, acting as the reference point for this image.
- Prompt input: “Using the uploaded image as the raw file, I would like you to help me make my portrait more appealing, resembling a professional photo shoot in ideal lighting conditions. I would like you to bring the background to perfect contrast with the suit worn by me in this photograph. You could improve the lighting on my face, include a bokeh effect with a blur gradient. And finally, I would like you to change the colour of my suit from grey to vibrant navy blue. Add finishing touches the way a photographer would using adobe photoshop for post processing. and present the highest quality image you can generate.”
- Guidance parameters: Select the image processing model you would like to use, such as Flux, Stable Diffusion, Midjourney, or any LLM model available. This is done by defining the checkpoints accessed guidance flow. (Advanced tweaking for pros)
In the above, the user is referring to himself as the person within the portrait uploaded as an image file. The prompt input acts as the guidance instructions that navigate the LLM to make any changes to the uploaded image, which the LLM now considers as noise and a reference point to make further changes. When the LLM begins the task of recreating the image, in reality, it makes an identical copy of the input to make changes and then starts rearranging the pixels within the image to obtain a specific desired image, guided by the prompt. Each pixel rearrangement that the LLM does can be considered as one step in reaching the desired output, where the LLM carries out a series of such pixel rearrangements to match the prompt input via an image output. The last bit is done by sequential encoding and decoding operations. Every step taken gets the LLM a bit closer to the final goal. This process is called diffusion, wherein a set of algorithms generate images by gradually transforming random noise (our input image) into meaningful content (the edited image).
Lets understand how this happens inside the Flux LLM models, and to simplify the explanation and related to established hypothesis, we will make use of ComfyUI as the visual interface that simplifies the usability of Flux LLMs.
In the below image, you will find the ComfyUI displaying a specific output for a given prompt. Let's consider this output to understand how the LLM arrived at it, navigating itself through the provided prompts and guidance protocols.
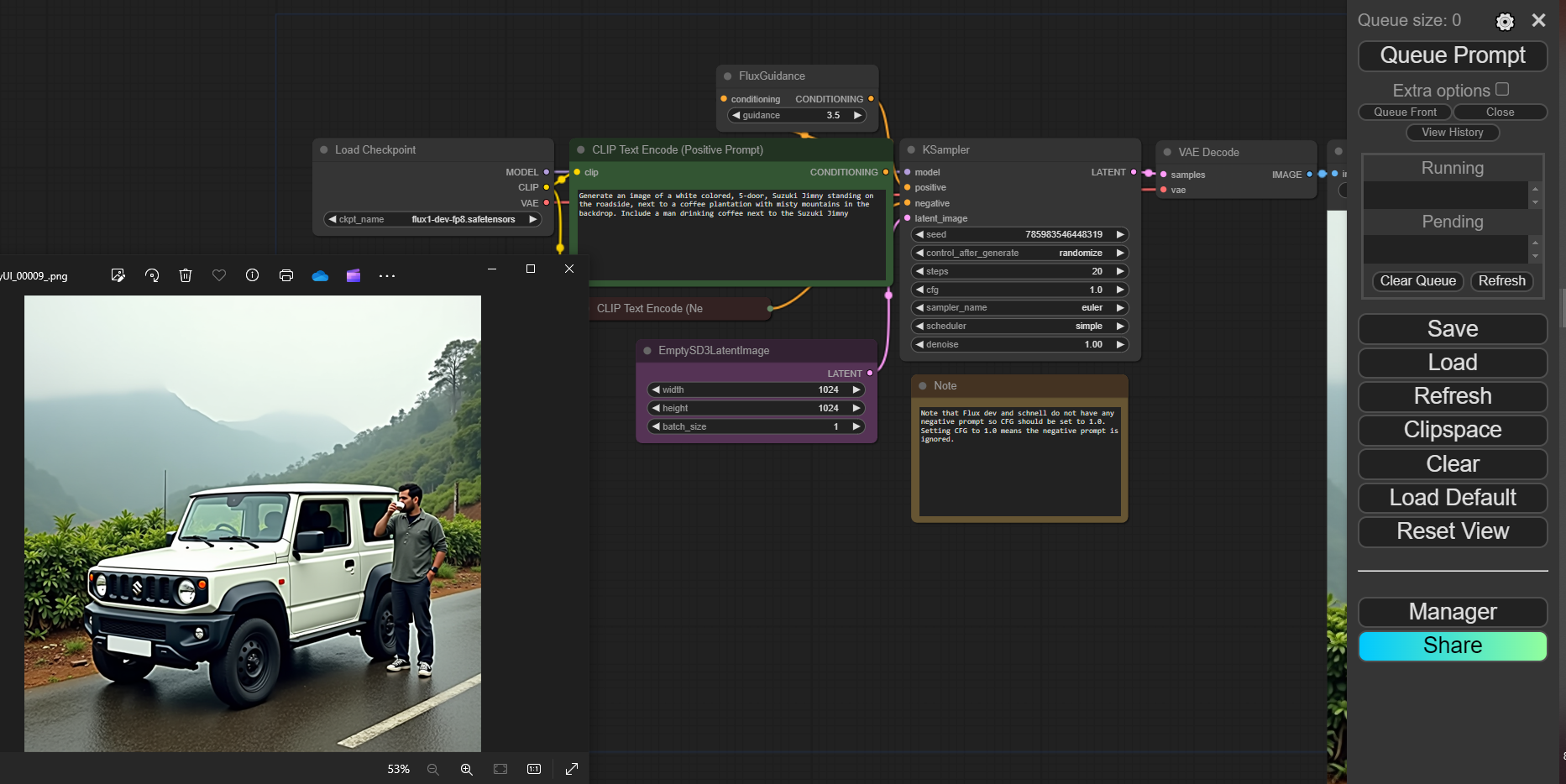
The image on the left hand side is the output obtained through the process of image generation using diffusion principles.
Firstly, to generate an image from scratch, without necessarily having a reference point to begin with, we need to select the correct LLM that stays true to our ideal expected output. As in the above case, we have gone with the flux1.dev model for the type of output it has successfully generated over several iterations, resulting a photorealistic output when prompted with the above configurations. For a simpler understanding, let's break down each of those components to understand how Flux generates this specific output.
The above image features 7 boxes, which allow users to change the input that is fed into the LLM to generate the image on the left-hand side. We have described these 7 components as per 4 criteria: purpose, function, type of control provided over output when in use, and an example of change noticed when said component is tweaked.
1. Load Checkpoints
- Purpose: Load pre-trained models or checkpoints that define the specific behavior and capabilities of the Flux model.
- Function: Determines the initial state and parameters of the Flux model, influencing the generated images.
- Control: Users can select different checkpoints to experiment with different styles, subject matters, or levels of detail.
- Example: Loading a checkpoint trained on a specific dataset (e.g., anime, landscapes) will influence the generated images to have similar characteristics.
2. Text Encoders
- Purpose: Encode text prompts into a numerical representation that the Flux model can understand. Here, text input is translated into machine language, and then the generated machine language-based output is decoded back to image outputs.
- Function: Determines how the model interprets and processes the textual descriptions.
- Control: Users can customize the text encoder or use different encoders to experiment with different interpretations of the prompt.
- Example: Using a more advanced text encoder might lead to more nuanced and detailed image generations. CLIP (Contrastive Language-Image Pre-training) is a more advanced encoder compared to traditional text encoders.
3. Conditioning within Flux Guidance
- Purpose: Provide additional information or constraints to guide the image generation process.
- Function: Influences the model's output by introducing specific elements or styles.
- Control: Users can provide conditioning images, masks, or other data to shape the generated image. This corresponds to the reference point that is established when an image is fed as the input, along with a text prompt and guidance protocols supporting it.
- Example: Using a mask to specify a region of the image to focus on can influence the generated details in that area. From the above example,
4. Empty3D3latentImage
- Purpose: A placeholder for the latent representation of the generated image. In instances where an initial image is used as a reference, the placeholder starts with this latent representation to create multiple series of improvisations, leading to the final output image.
- Function: Serves as a starting point for the image generation process.
- Control: Users can modify the initial values of the latent image to influence the generated image.
- Example: Randomizing the initial values can lead to more diverse and unexpected results.
5. KSampler
- Purpose: Determines the algorithm used to generate images.
- Function: Influences the quality, speed, and style of the generated images.
- Control: Users can select different samplers (e.g., Euler, DPM++) to experiment with different trade-offs between speed and quality.
- Example: Using a slower sampler like LMS might produce higher-quality images.
6. VAE Encoder
- Purpose: encodes the generated image into a latent representation.
- Function: Converts the high-dimensional image data into a lower-dimensional representation.
- Control: Users can adjust the parameters of the VAE encoder to influence the quality and detail of the generated images.
- Example: Modifying the VAE encoder's architecture can affect the level of detail captured in the generated images.
By understanding these components and their interactions, one can effectively control the Flux guidance process to achieve desired image generation outcomes. Experimentation with different settings and combinations of these components will help users fine-tune the process to produce the desired results.
Now that we have explained the different types of control one can get over the image generation process, we invite you to tweak the values the way we have in the above example and let us know the types of results you are able to obtain. We have laid out the steps to install flux locally on any computer with a minimum GPU (minimum 8 GB) capacity.
Below are the different types of output we were able to generate by simply changing the prompt.
Prompt:
Generate an Image for the following:
Subject: a white colored, 5-door, Suzuki Jimny
Action: standing on the roadside next to a coffee plantation with misty mountains in the backdrop.
More Context: Include a man drinking coffee next to the Suzuki Jimny
Art form: **Photorealistic image**

Prompt:
Create an image for the following:
Subject of the Image: A curious cat exploring a deserted alley
Action: Peering into a glowing box
Time and Day: Midnight under a full moon
Art Form: **Illustration**

To check out the Flux Guidance parameters used to generate these images, simply download them, drag and drop the same within the running instance of comfyUI, and the guidance parameters will be re-calibrated as per the settings used to create the image. Such is the beauty of ComfyUI running Flux models.
Some of the promising conversations had within Codemonk’s enterprise network were about the discrete, localized implementation of image generation, processing, and modification capabilities across enterprise use cases. This level of control in the above processes empowers us to deliver specific business outcomes for our clientele. We invite you into these value-driven discussions. Reach out to us for more.
Recommended reading:
Installation of Flux Models through ComfyUI
The Compute-Optimal Approach to Training large language models (LLMs)